Running Sovereign LLMs with vLLM and llm-d: A Practical Guide to Efficient Inference
A practical guide to running sovereign LLM inference with vLLM, llm-d, private infrastructure, and resource-controlled deployment patterns.

Running Sovereign LLMs with vLLM and llm-d: A Practical Guide to Efficient Inference
As AI adoption deepens across sectors, the need to run Large Language Models (LLMs) in sovereign, secure, and resource-controlled environments is greater than ever. Whether you're deploying in a private cloud, an on-prem server, or even an air-gapped laptop — choosing the right runtime is crucial for performance, privacy, and control.
In this article, I’m sharing insights from building and optimizing sovereign AI solutions using two standout LLM runtimes: vLLM and llm-d.
🤖 What is an LLM?**
LLM is a pre-trained AI model capable of understanding and generating human-like text. Examples include LLaMA 3, Mistral, GPT-4, and others. These models are at the core of chatbots, search engines, summarization tools, and RAG (Retrieval-Augmented Generation) systems.
However, running them efficiently and cost-effectively — especially outside the cloud — is the real challenge.
⚙️ What is a Runtime or Inference Engine?
An inference engine or LLM runtime is software that helps run the LLM during prediction time — i.e., when you're asking it questions, not training it. It handles:
- Token generation
- Batching multiple requests
- Optimizing GPU or CPU usage
- Streaming responses
Think of it as the engine behind the scenes that takes your prompt and turns it into an intelligent answer — fast.
🟢 Introducing vLLM
vLLM is a high-performance LLM inference engine designed for GPU-based deployment. 🔧 Built by: UC Berkeley and contributors 🚀 Key Feature: Uses PagedAttention to significantly reduce GPU memory fragmentation and improve throughput.
🔑 Features:
- Continuous batching (serve multiple users efficiently)
- Streaming token output
- Hugging Face model support (no conversion needed)
- Perfect for serving LLaMA, Mistral, Falcon, and other PyTorch-based models on GPU
📦 Use Case:
Deploying a sovereign or enterprise-grade GenAI service on GPU hardware, with high load and concurrency needs.
🟠 Introducing llm-d
llm-d (LLM Daemon) is a lightweight, fast inference server that uses llama.cpp internally to serve quantized GGUF models (LLaMA, Mistral, etc.) efficiently on CPU or GPU. Though the official GitHub repository (llm-tools/llm-d) is currently unavailable, it was previously accessible and tested internally. It’s a useful concept in designing sovereign AI runtimes.
✅ Key Features:
- REST & WebSocket API
- Runs locally or in air-gapped environments
- Supports multiple models simultaneously
- Perfect for edge devices, developer laptops, and internal systems
📦 Use Case:
Ideal for local RAG projects, testing, small-team deployments, or where GPU is not available.
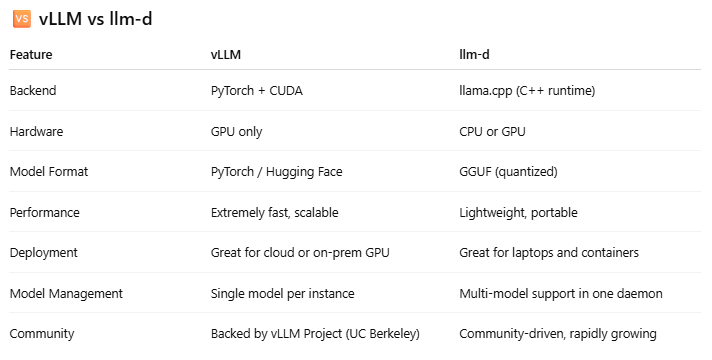
🧩 vLLM and llm-d Together?
Yes — they’re complementary, not competing.
Here's a real architectural diagram from llm-d:
This shows:
- llm-d using vLLM as a backend
- Routing logic, cache, and inference schedulers
- Modular execution of LLM tasks, depending on load and model
🛡️ Sovereign RAG Architecture Example
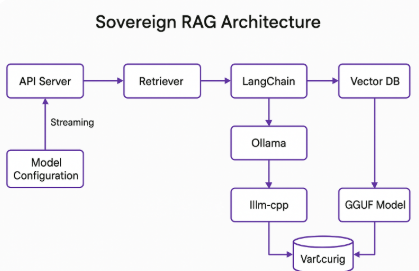
🔎 Sovereign RAG Flow Explained:
- 1. API Server: Accepts user queries and serves the frontend.
- 2. Model Config: Manages LLM parameters (model name, tokens, temperature).
- 3. Retriever: Searches semantic vector DB for relevant documents.
- 4. LangChain: Orchestrates the RAG flow, including prompt + context formatting.
- 5. Vector DB: Stores and indexes vector embeddings.
- 6. Ollama: Local LLM server that wraps llama.cpp and handles streaming.
- 7. llama.cpp: Performs the actual GGUF model inference on CPU/GPU.
- 8. GGUF Model: Efficient quantized model files (e.g., llama3-3b.Q4_K_M.gguf).
This entire pipeline is containerized and fully local — no cloud dependencies.
✅ Summary
- LLM = the brain (LLaMA, Mistral, GPT)
- vLLM / llm-d = the engine that runs it
- For sovereign AI, local and efficient LLM runtimes are a must
- vLLM is GPU-focused; llm-d / Ollama / llama.cpp are CPU-friendly
- Together, they form the backbone of scalable, private GenAI infrastructure
🚀 My Take
In my work building sovereign AI solutions, tools like vLLM and llm-d have proven instrumental.
When deploying on GPU-backed infrastructure, vLLM consistently delivers outstanding throughput and responsiveness — making it ideal for production-scale workloads.
On the other hand, for local, edge, or resource-constrained environments, llm-d (and similar runtimes like Ollama or direct use of llama.cpp) make it incredibly easy to spin up private LLM endpoints — without cloud dependencies or heavyweight frameworks.
If you're serious about building LLM applications that are fast, private, and infrastructure-aware, it's worth exploring both ends of the spectrum and choosing a runtime that fits your latency, privacy, and cost profile.
📌 Resources:
🔗 vLLM: https://github.com/vllm-project/vllm 🔗 llm-d: https://github.com/llm-d 🔗 llama.cpp: https://github.com/ggerganov/llama.cpp